Zusammenfassung
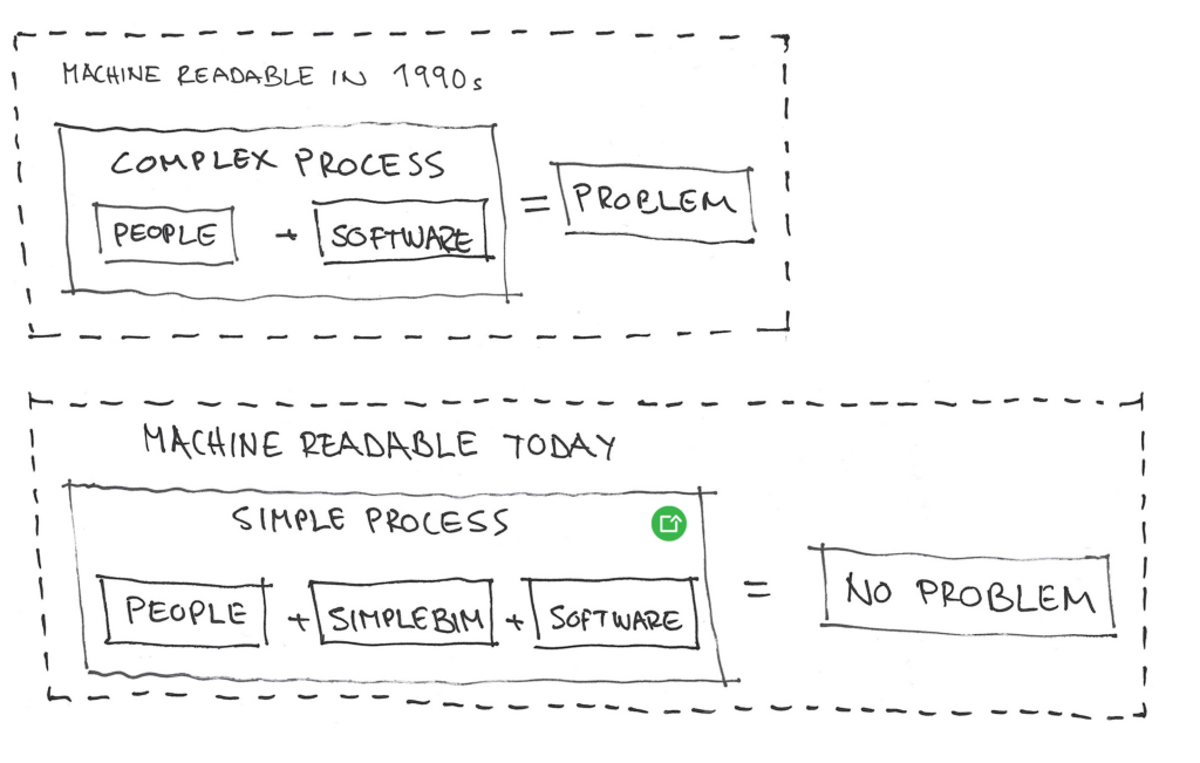
Die Denkweise, dass Probleme beim BIM-Datenaustausch primär durch Menschen und Software verursacht werden, führt zu komplexen Prozessen, die trotz drei Jahrzehnten intensiver internationaler Zusammenarbeit in realen Projekten kaum Erfolgsaussichten haben. Die Ursache dieser Denkweise liegt in einer Definition von „maschinenlesbar“ aus den 1990er Jahren.
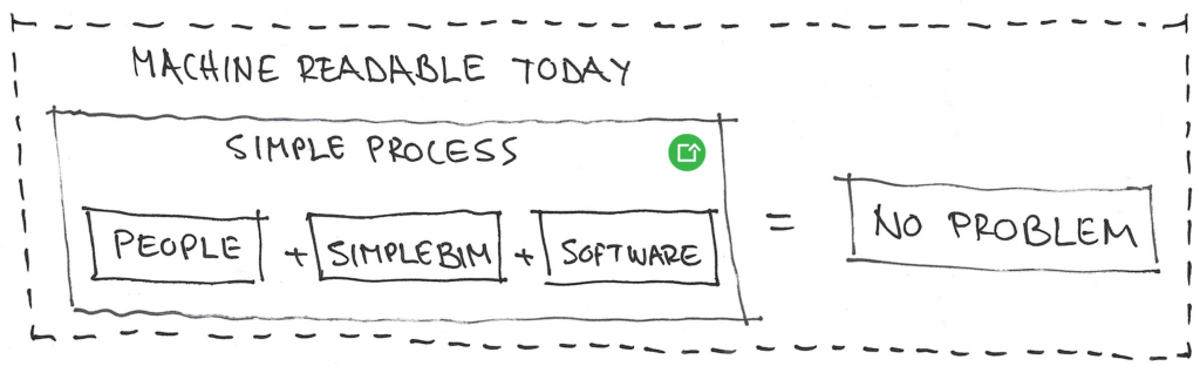
Eine Aktualisierung dieser Definition auf den heutigen Stand ermöglicht es uns, den BIM-Austausch mit einer neuen Mentalität anzugehen, die zu einem wesentlich einfacheren Prozess führt.
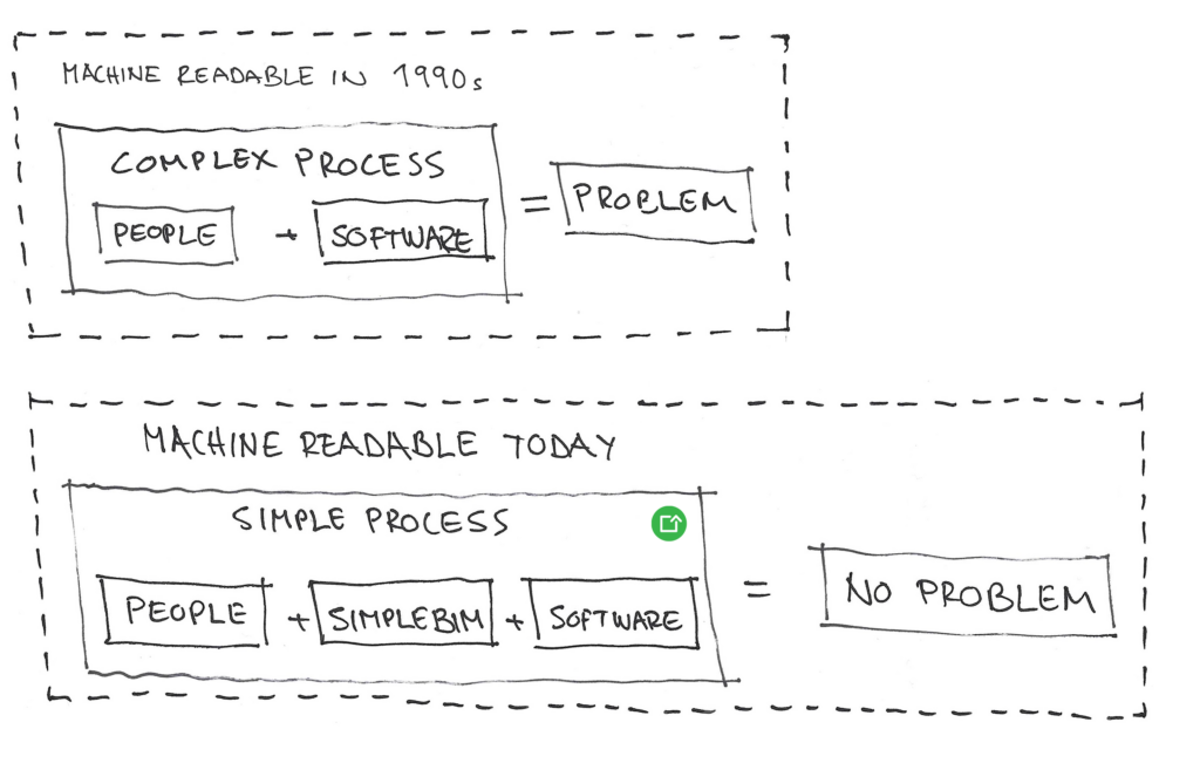
Dieser neue Prozess zeichnet sich durch radikal reduzierte BIM-Anforderungen aus und verringert die Abhängigkeit von Spezifikationen, Gesetzen, Vereinbarungen, Modellprüfungen, Fehlermanagement (Issue Management) und BIM-Koordination.
In der Praxis wird dieser neue Prozess durch eine neuartige Software wie Simplebim® ermöglicht, die wir bereits seit 16 Jahren entwickeln und die weltweit bereits in tausenden Projekten täglich im Einsatz ist.
Es gibt ein Problem mit BIM
Es ist offensichtlich, dass es ein Problem mit BIM gibt, da es auch nach drei Jahrzehnten konzentrierter internationaler Bemühungen seine Versprechen immer noch nicht einlöst. In all diesen Jahren gab es zahlreiche Entwicklungen, die die Situation eigentlich verbessern sollten. Dazu gehören die Nutzung von XML und später JSON anstelle von STEP, neue IFC-Versionen, Model Views (MVDs), Model-Server, Modellvalidierung in verschiedenen Varianten, Issue Management, Software- und Berufszertifizierungen, Common Data Environments (CDEs) – und die Liste ließe sich fortsetzen.
In diesem Beitrag präsentiere ich sowohl eine Erklärung als auch eine Lösung für diese Situation.
Die gängige BIM-Denkweise
In der internen Anwendung funktioniert BIM recht gut, doch die eigentlichen Probleme beginnen beim BIM-basierten Datenaustausch. Es ist eine schwierige Aufgabe, verlässliche, konsistente und qualitativ hochwertige BIM-Daten von Dritten zu erhalten. Der derzeitige Mainstream-Ansatz beim BIM-Austausch versucht zu lösen, wie man die Planer dazu bringt, genau solche Daten zu liefern. Mit dieser Denkweise lassen sich zwei Hauptschuldige für die aktuelle Lage identifizieren: der Mensch und die Software.
Das Problem von Mensch und Software lösen
Das „Problem Mensch“ könnte man theoretisch durch Ausbildung und das Festlegen von BIM-Austauschanforderungen lösen – bis hin zu gesetzlichen Verpflichtungen. Da Menschen jedoch Fehler machen, besteht die sekundäre Lösung darin, Modellprüfformate (wie IDS), Software für Modellprüfung und Issue Management sowie entsprechende Kommunikationstools in Common Data Environments (CDEs) zu entwickeln – all das unter der Aufsicht von BIM-Koordinatoren. Und da auch Software Probleme verursachen kann, haben wir MVDs (Model View Definitions), Software-Zertifizierungen und lange Listen von Funktionswünschen an die Softwarehersteller…
Das eigentliche Problem ist die Denkweise
Das alles klingt zunächst plausibel – doch diese Denkweise bringt zwei massive Probleme mit sich.
Das erste Problem ist, dass das gesamte System extrem komplex ist. Und Komplexität verringert in der Praxis immer die Chancen, dass etwas in realen Situationen tatsächlich funktioniert.
Wir haben hier in Finnland bereits um 2005–2006 unter „Laborbedingungen“ und mit beträchtlichen Forschungsgeldern bewiesen, dass der BIM-Datenaustausch in realen Projekten technisch funktionieren kann. Aber dasselbe in „normalen“ Projekten zum Laufen zu bringen, ist eine ganz andere Geschichte. Finnland kann zum Beispiel auf nationaler Ebene eine ordentliche Fußballmannschaft zusammenstellen – das bedeutet aber noch lange nicht, dass wir Finnen als Nation insgesamt gut im Fußball sind. Genauso war es schon vor 20 Jahren möglich, ein gewinnbringendes BIM-Team aufzustellen, aber das bedeutet nicht... Sie verstehen, worauf ich hinauswill.
Das zweite Problem betrifft den Zeitfaktor. Ich persönlich arbeite bereits seit 28 Jahren an der Lösung von Problemen beim BIM-Datenaustausch. Die Frage ist: Wie viel Zeit kann man einer Idee vernünftigerweise geben, bevor man akzeptiert, dass mit ihr vielleicht etwas grundlegend nicht stimmt?
"Maschinenlesbarkeit“ neu bewerten
Basierend auf diesen Überlegungen schlage ich eine andere Denkweise vor. Das Hauptziel des BIM-Austauschs ist es, Informationen in einer maschinenlesbaren Form zu übertragen. Das ist es, was BIM von Zeichnungen und anderen Dokumenten unterscheidet – es ist quasi der Sinn der ganzen Übung. Das ist zwar nach wie vor richtig, aber die internationale BIM-Community marschiert seit den 1990er Jahren vorwärts, ohne jemals innezuhalten, um neu zu bewerten, was „maschinenlesbar“ eigentlich bedeutet. Und das, obwohl niemand, der bei klarem Verstand ist, behaupten würde, dass maschinenlesbar heute dasselbe bedeutet wie vor 30 Jahren! Unser gemeinsames Ziel auf der „Ideen-Ebene“ ist immer noch dasselbe, aber gleichzeitig hat es sich auf der „technischen Ebene“ verändert – und wir müssen diesen Wandel anerkennen.
„Maschinenlesbarkeit“ in den 1990er Jahren
Die Definition von maschinenlesbar aus den 1990er Jahren ist sehr streng, und die aktuelle Verwendung des IFC-Modells spiegelt dies wider. Wenn Sie beispielsweise eine Information austauschen möchten, müssen Sie exakt die richtige IFC-Objektklasse mit dem richtigen vordefinierten Typ verwenden. Dann müssen Sie ein exaktes Property-Set und eine Eigenschaft (Property) verwenden, die beide absolut korrekt geschrieben sein müssen – einschließlich Leerzeichen und Groß-/Kleinschreibung. Schließlich müssen Sie Eigenschaftswerte verwenden, die wiederum exakt aus einer Liste zulässiger Werte stammen, natürlich wieder mit exakt übereinstimmender Schreibweise. Nur wenn all dies gegeben ist, gilt das Ergebnis als „maschinenlesbar“.
Hier ist die Übersetzung für diesen abschließenden, starken Vergleich:
„Maschinenlesbarkeit“ heute
Aber mal ehrlich: Funktioniert heute noch irgendetwas anderes, das Sie an Ihrem Computer tun, auf diese Weise? Damals war der Grund für diese strikte Definition die begrenzte Rechenleistung und die eingeschränkten Softwarekapazitäten.
Heute, da wir über leistungsfähigere Computer und fortschrittlichere Software verfügen, sollten wir in der Lage sein, die Definition von „maschinenlesbar“ zu lockern. In der Praxis bedeutet dies, dass wir mit deutlich weniger BIM-Anforderungen und damit verbundenen Gesetzen, Spezifikationen, Vereinbarungen, Modellprüfungen, Issue Management und BIM-Koordination auskommen – und dennoch die gewünschte Maschinenlesbarkeit erreichen.
Nein, ich spreche nicht von KI
Jetzt denken Sie vielleicht sofort an Künstliche Intelligenz, aber in diesem Szenario ist KI nur die Spitze des Eisbergs. KI kann zwar Teil der Lösung sein, aber sie ist nicht die vollständige Lösung – und die meisten Dinge lassen sich mit dieser neuen Denkweise auch ganz ohne KI lösen.
Wem vertrauen Sie?
Über die Jahre hat sich herausgestellt, dass im realen Einsatz „Vertrauen“ einer der Schlüsselfaktoren beim BIM-Datenaustausch ist. Die Frage ist: Wem oder was entscheiden wir uns zu vertrauen?
Das ist eine komplexe Frage, aber die kurze Antwort lautet: Wir können darauf vertrauen, was die Ersteller von Informationsmodellen für ihre eigene Arbeit benötigen. Wir können diesen Informationen am meisten vertrauen, wenn sie so strukturiert sind, wie der jeweilige Ersteller sie ohnehin versteht und nutzt. Wir können beispielsweise darauf vertrauen, dass ein Architekt den Namen eines Raumes korrekt angibt, weil Räume für die eigene Arbeit des Architekten essenziell sind.
Wir können jedoch weniger Vertrauen in die exakte Schreibweise haben („Elektroraum“ könnte auch als „ELT“ abgekürzt sein) und noch weniger in das Mapping dieser Information nach IFC (die Information könnte in einer benutzerdefinierten Eigenschaft versteckt sein). Aber was wäre, wenn es ausreichen würde, den Raumnamen einfach in einer verständlichen Weise irgendwo im Modell zu haben? Wenn dies möglich wäre, könnten wir fast alle aktuellen BIM-spezifischen Anforderungen an Raumnamen streichen – und nur die reinen Informationsanforderungen blieben übrig.
Neue Denkweise, neue Art von Software
Man erkennt schnell: Die Neudefinition von „maschinenlesbar“ allein löst als bloße Idee noch keine realen Probleme – aber sie öffnet uns die Augen für neue Möglichkeiten. Wir können nun anfangen darüber nachzudenken, welche Art von Software wir benötigen, um diese Idee in die Tat umzusetzen.
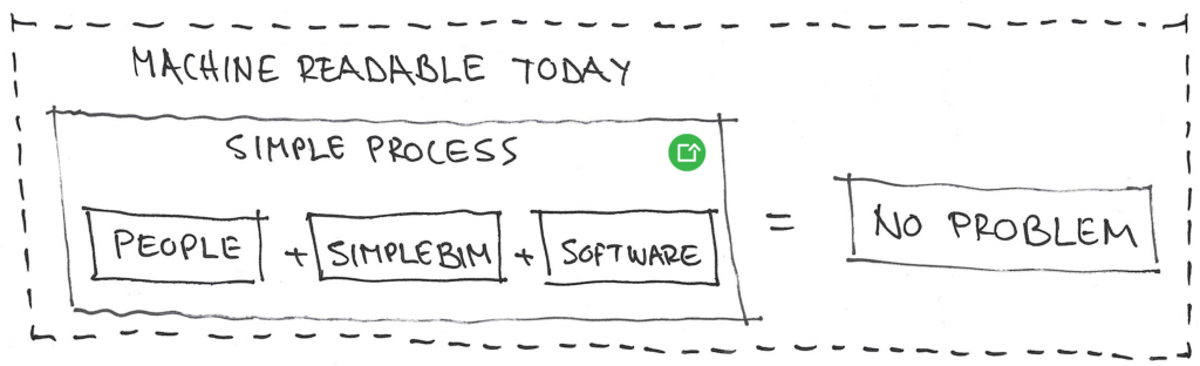
Glücklicherweise haben wir diesen Weg bereits vor 16 Jahren mit der Entwicklung von Simplebim eingeschlagen: Wir können nicht erwarten, dass jede Software diese zeitgemäße Definition von Maschinenlesbarkeit sofort übernimmt und umsetzt. Aber wir können Software einsetzen, die die semantische Lücke zwischen Mensch und Computer schließt. So können Menschen einfach „Mensch sein“ – und wir profitieren dennoch von allen Automatisierungsvorteilen, die BIM bietet.
Datenflüsse mit Simplebim einrichten
In Simplebim würde das Beispiel mit dem Raumnamen durch einen Dataflow (Datenfluss) gelöst. Dieser wird einmal definiert und dann wiederverwendet, um den Prozess vollständig zu automatisieren.
Zuerst müssen wir die Raum-Objekte finden, typischerweise IfcSpace-Objekte. Aber nicht alle IfcSpace-Objekte sind tatsächliche Räume, da es sich auch um Brutto-/Nettoflächen, Wohnungen oder Ähnliches handeln kann. In Simplebim müssen die Räume nicht einmal zwingend als IfcSpace-Objekte vorliegen. Dann scannen wir die Raum-Objekte nach typischen Eigenschaften, welche die Raumnamen-Information enthalten könnten, und erweitern diese Liste bei Bedarf um neue Eigenschaften. Im nächsten Schritt kopieren wir den Raumnamen von dort, wo wir ihn gefunden haben, dorthin, wo er nach der strengen Definition von Maschinenlesbarkeit hingehört: in die Eigenschaft LongName von IfcSpace. Schließlich können wir einfache „Suchen und Ersetzen“-Operationen durchführen, um beispielsweise „ELT“ durch „Elektroraum“ zu ersetzen.
Bei Bedarf können wir sogar die Objektklasse konvertieren – zum Beispiel von IfcBuildingElementProxy zu IfcSpace. Wir können zudem Mengen und Maße aus der Raumgeometrie berechnen, Boden- und Wandflächen generieren sowie Fenster, Türen, Steckdosen usw. den entsprechenden Räumen zuordnen.
Der letzte Schritt besteht darin, das Ergebnis wieder nach IFC zu exportieren und in jeder IFC-fähigen Anwendung zu nutzen.
Ein besserer Prozess löst das Problem
Für den BIM-Prozess bedeutet dies in unserem Beispiel, dass die Architekten zwar nicht „einfach irgendetwas“ machen können, die Kernanforderungen jedoch bestehen bleiben: Räume müssen mit angemessener geometrischer Genauigkeit modelliert und mit einem Namen versehen werden. Aber das sind alles Dinge, bei denen wir darauf vertrauen können, dass der Architekt sie richtig macht, weil er diese Informationen auch für seine eigene Arbeit benötigt.
Was sich ändert, ist, dass wir keine Dinge mehr verlangen, die Architekten weder brauchen noch im Detail verstehen müssen – wie etwa die Nutzung von IfcSpace, dem vordefinierten Typ SPACE, das Attribut IfcSpace.LongName oder daß Raumnamen exakt einer von uns vorgegebenen Liste entsprechen müssen. Zudem liegen manche Aufgaben klar außerhalb des Verantwortungsbereichs der Architekten, wie etwa die Zuordnung von Steckdosen zu Räumen, was ohnehin das Zusammenführen mit dem Elektro-Modell erfordern würde.
Am Ende vereinfacht all dies den BIM-Datenaustausch-Prozess erheblich – und macht es viel wahrscheinlicher, dass selbst eine Fußballmannschaft aus der 3. Liga in jedem Spiel ein Tor schießt!
Über den Autor
Jiri Hietanen ist Mitbegründer und CEO von Datacubist sowie der Chefarchitekt von Simplebim. Als studierter Architekt verfügt er über mehr als 25 Jahre Erfahrung in den Bereichen IFC, BIM und Softwareentwicklung. Sein Fokus liegt auf der Entwicklung neuer Lösungen für skalierbare BIM-Datenverarbeitung, Automatisierung und OpenBIM-Workflows.
Simplebim testen
Testen Sie Simplebim mit Ihren eigenen IFC-Daten 7 Tage kostenfrei!
